⚡️ Learn how to automate repetitive work with 1:1 help from a Software Engineer → https://www.skool.com/ai-academy-with-robby-6849/about
Hi! I’m Robby.
I spend my days building AI systems, and one of the most common questions I get is: "How does a computer actually learn from its mistakes?"
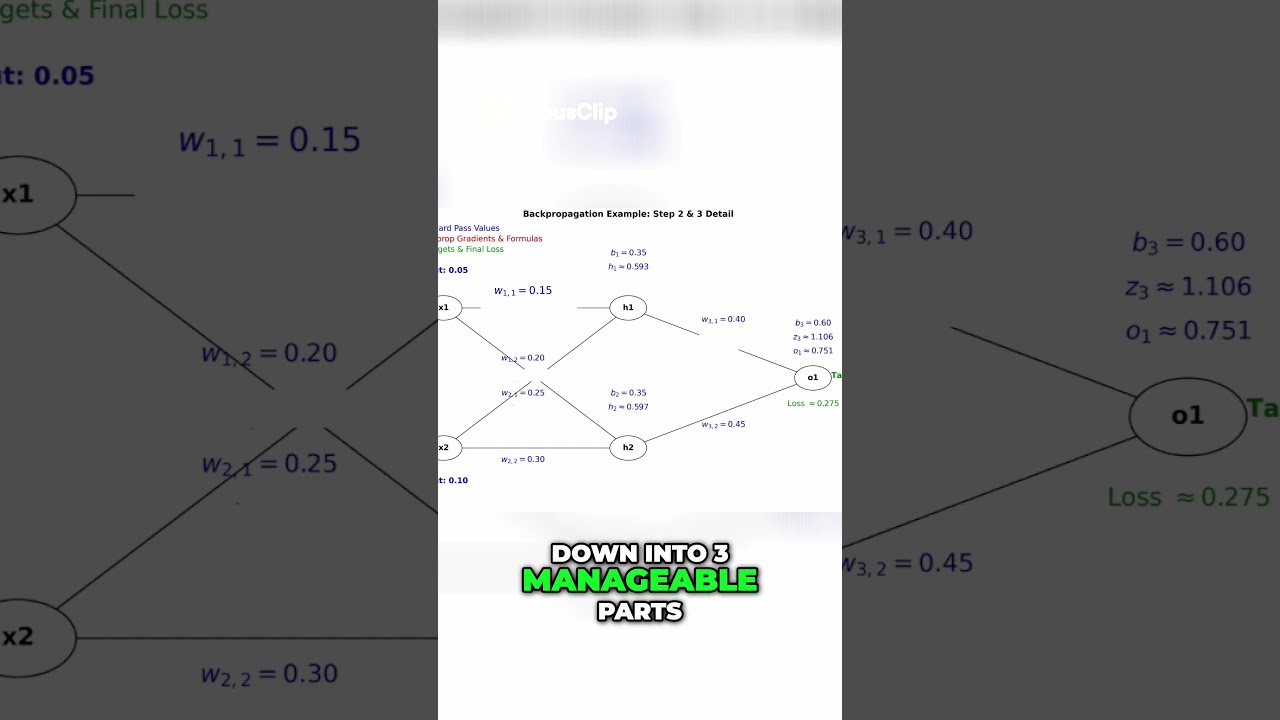
It sounds like magic, but it’s actually just a big game of pointing fingers. We call this process backpropagation. Let’s break it down.
The Forward Pass: Making a Guess
Imagine a neural network as a giant team of workers. In the beginning, the network makes a guess. If the guess is wrong, we have an error. But which worker made the mistake? Was it the one at the start, the middle, or the end?
Playing the 'Blame Game'
To fix the mistake, we have to play the Blame Game. We need to look at every single connection (we call these weights) and decide how much that specific connection helped cause the wrong answer.
If a weight was barely involved, we don’t blame it much. If it was a big part of the mistake, we blame it a lot so it can change for next time.
The 3 Secrets of the Chain Rule
To calculate this blame, we use a math tool called the Chain Rule. Think of it like three simple steps:
- The Mistake: First, we calculate how far off our final answer was. That’s our error.
- The Sensitivity: Next, we look at the neuron to see how sensitive it is to changes. If a tiny change makes a big difference, we pay close attention.
- The Input Strength: Finally, we look at the input signal.
Why the Input Matters
This is the most important part. If a previous neuron sent a zero signal, the weight couldn't have caused the mistake because it didn't do anything!
We multiply by the input to make sure we only blame the connections that were actually "awake" and working during the mistake. If the input is zero, the blame is zero.
How AI Gets Smarter
Once we finish the Blame Game, we have our "gradient." This is basically a map that tells us how to tweak each weight to make the next guess a little bit better.
By repeating this millions of times, the network learns. It’s not just guessing anymore—it’s getting smarter, one correction at a time!